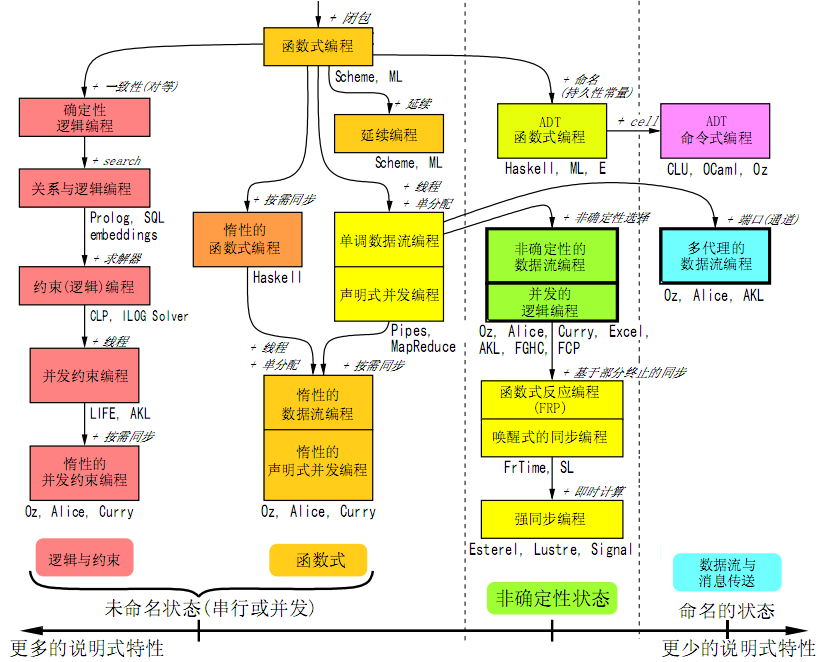
“主要的编程范型”(The principal programming paradigms)这幅图,其实出现得不算早,作者在2007年完成了该图的1.0版,到2008年更新至v1.08版本。本次提供的是翻译成中文的版本(老实说,笔者翻译水平相当有限,若有不当之处,请各位尽量指出,必尽快补正)。
这幅图的原作者Peter Van Roy,是《Concepts, Techniques, and Models of Computer Programming》一书的作者,这本书(CTM)是少有的、能跟SICP并称的书了。
该图原文档(PDF)下载:http://www.info.ucl.ac.be/~pvr/paradigmsDIAGRAMeng108.pdf
该图中文翻译文件(PDF)下载在这里。
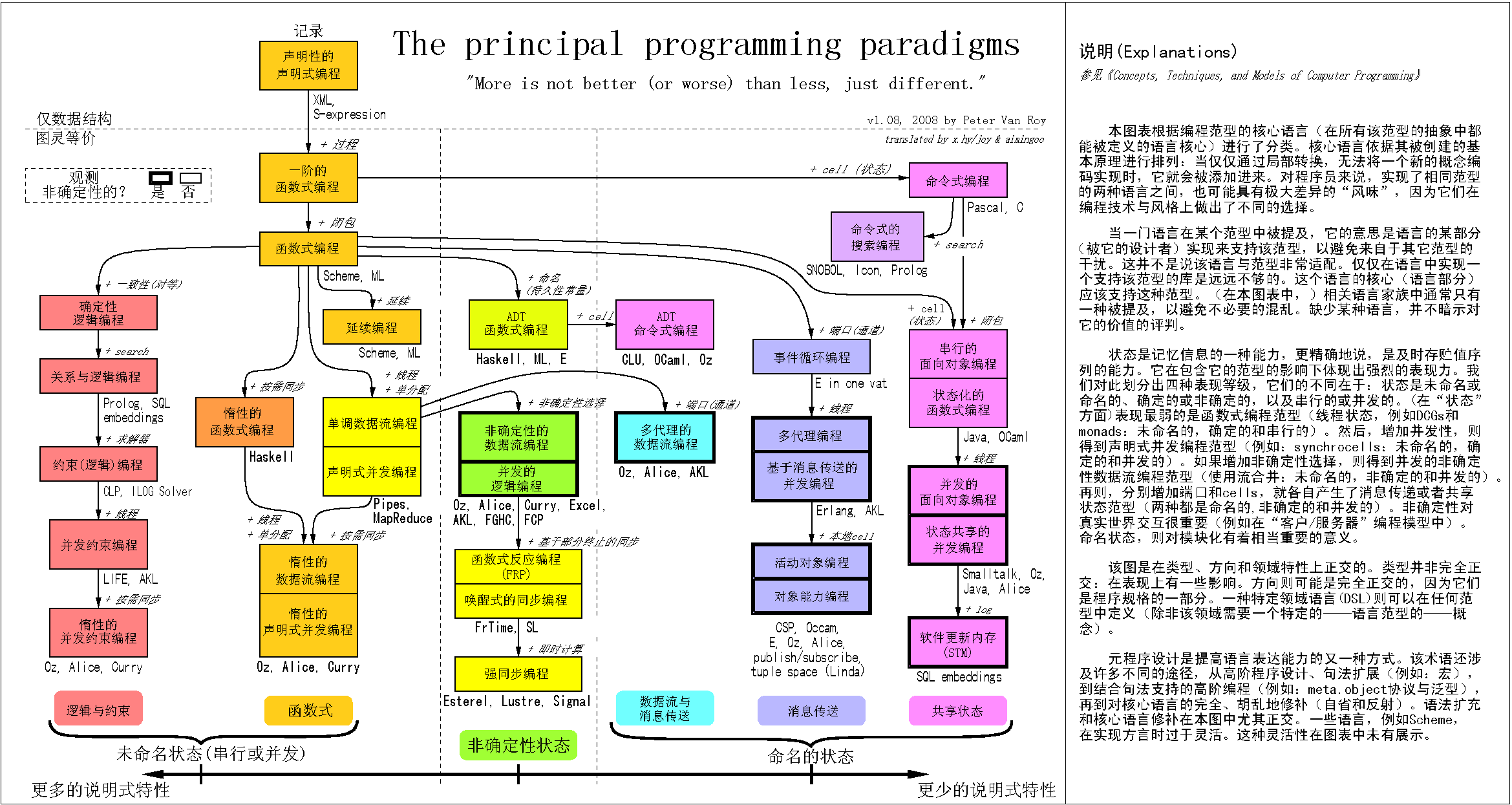
(图1)主要的编程范型(点击查看大图)
一、从数据到编程
Peter在“主要的编程范型”中,首先分清了数据描述语言与描述式编程语言。他把数据描述语言——例如XML——作为独立部分划分出来,然后指出这类语言主要考虑数据结构的描象,理论上基于人们对结构(记录/Record、结构/Struct)的理解。接下来,作者在此基础上引入第一种“程序设计特性”,即procedure,由此得到“初阶函数式编程”这一个基本的程序设计范型。
从这里可见Peter在程序设计语言分类上与以前的其它方法的不同之处:Peter并不在乎语言出现的时间关系,也不在乎语言的流行程度的影响。他着力于观察语言特性发展之间的脉络。而必须要对上述内容补充说明的是,Peter在“初阶函数式编程”所说的函数,事实上是早期业界对“函数(function)”的定义,即:例程分为过程、函数两种,二者区别仅在于前者不返回值,后者返回值。所以事实上,在这里Peter强调的是一种“普通例程”的特性。
二、最重要的分类依据:cells(state)
接下来,Peter将一个最重要的概念"state"引入进来。而这个state也是Peter对语言进行分类并考察它们的进化变化的主要依据。但是,Peter所引用的这个state概念,以及在这里使用的专用名词“cells”相当地令人迷惑,所以在这个图的补充说明中,Peter对此专门做了解释:“状态是记忆信息的一种能力,更精确地说,是及时存贮值序列的能力。”
你觉得这个概念象什么?对了,的确,非常象是“变量”。事实上,状态在编程核心概念的“数据-逻辑”抽象中,它表明的正是“数据的可变性”,亦即是说:数据的可变性表现为状态。更进一步地说:当数据被命名时,它称为变量或常量;当数据未命名时,它成为游离的、无名称和时序含义的存储单元,即“cells”。这也是Peter使用“cells”这个专用名词的原因:在本图的讨论中,需要从“变量/常量”这样的概念中,剥离掉“未命名或命名的、确定的或非确定的,以及串行的或并发的”这三方面的性质。
当不考虑一个存储位置上的命名特性时,它就既非变量、常量,也非某个确定的运算对象(例如“对象”等高级的抽象概念),而只是一种更加泛义的“状态”,而存储这个状态本身的,则因为没有位置、时序等概念,而称为“cells”。
三、命令式语言的诞生:状态维护
《程序设计语言》这本书解释过命令式语言的本质特性,即:用算法改变数据。如果用两个以上的逻辑(例如两行代码)去影响同一个存储位置(cells),并使它的状态改变,最终在该cell产生运算结果的,那么它就是一种命令式语言。
再简单一点(但没有上面这样严谨)地说:在程序中不断地重写变量,变量值即是程序的最终结果。
所以,在本图中,Peter把这个衍生关系表达为:命令式=纯数据+算法+状态维护。如图:
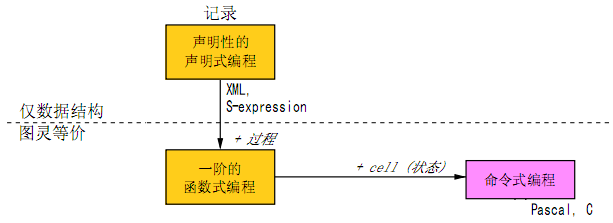
(图2)命令式语言的诞生
四、在命令式编程中对“状态”的理解:共享状态
无论是在串行的,还是并发的编程中,命令式编程范型对“状态”的理解都是:共享状态。在图中,这一分支表现为全部的桃红色(参见后图)。
在串行(例如单线程)的编程中,状态是时序相关的。因为不断地重写“状态(数据/cells/变量)”,所以前一行和后一行所面对都是同一个共享状态的不同的值/副本。在这个过程中,状态是时序相关的,所以前一分钟与后一分钟的状态是不确定的——但是在同一时刻,这个状态是确定的。
与上面类似的,在多线程中,同一时刻,不同线程也将面临这个值/副本。但是正是因为多线程(并发)中,线程A与线程B对于同一个cell,在同一时刻所得到的状态也是不确定的——我们可以假想为多核CPU在对同一个内存地址读写(于是就出现了我们所谓的“同步”问题,进而也就出现了“锁”的问题),所以在这个分支中,当加入“线程”概念之后,新的编程范型,全都变成了“观测-非确定性”为“yes”的情况。
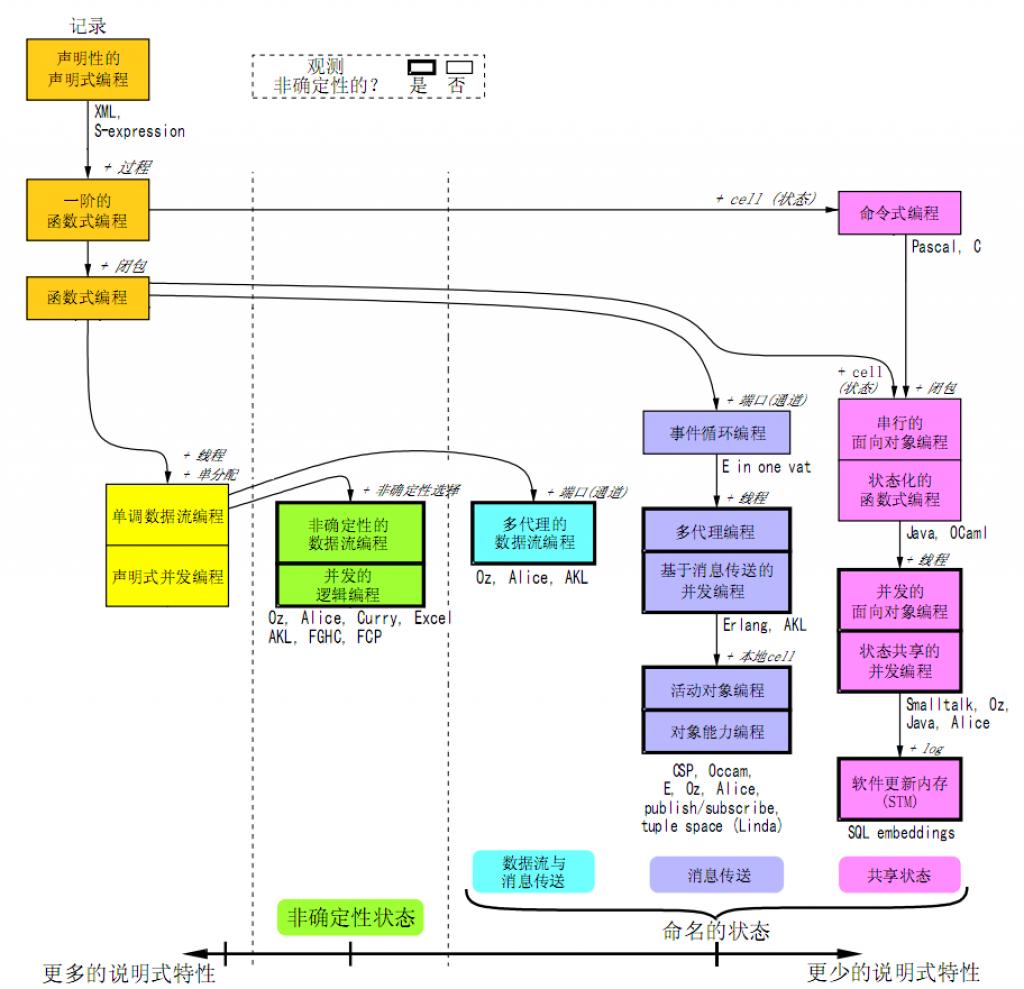
(图3)观测-非确定性(留意图中加粗的黑框),以及状态的共享
“观测-非确定性(Observable nondeterminism)”可以被译为“测不准”,但是用在中文中依然拗口,所以我选择了直译。在Peter的书(CTM)中,对该问题有一个经典的示例,即:
declare
C = {NewCell 0}
thread
C:=1
end
thread
C:=2
end
Peter这段代码的意思是说:当线程1和线程2,在同时向C这个cell写数据时,你并不确知上述代码运行之后C这个位置上的值究竟是1,还是2。
五、解决这个问题的终极之道:不要写cell!
我们显然发现,问题是因为多个线程都在“写cell”。在命令式的解决方案中,采用的方法是“加锁”;持锁存取的最经济的方法之一是“多读单写”——即保证同时只有一个线程能“写cell”。
但是这给应用带来了负担——如果一个应用程序由多个线程(分布或不分布在多个CPU核上),在它们都要读取同一个cell、而又有某个线程要写该cell的时候,那么大家就都要挂起来等这个写操作完成了。整个应用程序在CPU使用(或者说效率)上就大大地打了折扣。
如果这只是一个桌面程序(例如记事本),大概没人会说什么。但如果是服务器程序(例如Web Server),那么整个网络、所有的会话就都处于等待状态了——而这个时候,服务器的CPU占用还可能远远地小于1%!
解决问题的终极方法,就是不解决这个问题——写cell带来了问题,那么我们就“不写cell”。我们由前面所有讲述的内容开始倒推,问题根本是由“命令式语言”这个编程范型本身决定的:用算法改变数据。
所以,我们回到了原始的问题:如果算法不改变cell(数据/状态/变量)呢?
六、函数式编程的核心概念:闭包
当“过程(初阶的函数)”引入了“闭包”的概念后,整个“函数式语言”的体系建立了起来。所谓“闭包”,是指在函数运行的上下文中,所有的cells与函数之外无关,这些cells的状态仅与函数——这个运算逻辑相关,则这个上下文环境“整体地”被称为“闭包”。
如果换个说法,闭包就是不受函数之外影响的一堆cells。一般在实现它的时候,就是让函数持有一个“专属的(!)”内存块,并且这个内存块仅当函数本身失效的时候,才被释放。
一个“函数本身”何时失效呢?如果这个函数只有传入参数和传出值的功能,那么这个函数就在它传出值之后立即失效了。所以,对于整个运算逻辑——这个函数来说,它没有操作过任何(函数之外的)状态,既没有读,也没有写。对于这个逻辑来说,只有传入,也只有传出,所以它具有完全的运算确定性,它本身作为一个“结果值”来看的时候,也是确定的。
不过在实用时,对于上述的观念做出了一些挑战。例如说:当函数内部执行了一半的时候退出,怎么办呢?答案是:1、先不释放函数;2、过一会儿再进入。这个,就是所谓的延续(Continuation),以及在JavaScript 1.6以后推出的yield概念。同样的,正因为“的确存在”执行之后函数不释放的可能性,所以函数式语言通常是由语言引擎来维护闭包的生存周期的——任何新的概念、理论的提出,都必须保证这个生存周期可测、可维护。因此相较于命令式语言,自动内存管理在函数式语言中实现起来更为高效和简洁,它最早被实现在函数式语言(LISP)语言中,也是有其必然性的了。
这样一来,对于在函数之外的状态state来说,函数从来不去影响它们。函数式编程范型带来了新的模式:给函数数据(入口参数),函数给出结果(返回值)。即通过不断地函数运算来产生结果,而不改变cell(数据/状态/变量)。
函数式与命令式范型相比较,前者被人称为(P,D;I,O),后者被人称为(I,O;P,D),其中:输入(I)、输出(O)、加工处理程序(P)和存储状态数据(D)。即函数式先明确(P,D)——确定的处理与数据(闭包),然后讨论在闭包上的I、O问题。而命令式先确定了I、O的方式——即state的存取问题,然后讨论P、D的设计。
七、状态的命名:变量、常量、端口等
在整个这个“主要的编程范型”图中,也许最接近现实世界(通用应用开发)而又是纯函数式范型的语言,就是erlang了。从图中的标注来看,erlang具有这样的一些语言特性:
- 消息传递
- 命名状态
- 端口
- 闭包
- 线程(erlang中的轻量级进程)
这五个特性,其实都可以归结为erlang对“状态”的处理方式。其中:
- 当跨节点传递状态时,采用“端口+消息传递”;
- 当跨线程(进程)传递状态时,采用“进程ID+消息传递”;
- 当在多个函数/执行过程中传递状态的,采用“闭包(函数入口参数)”。
亦即是说,你可以把“端口、进程标识或函数入口参数”想像成“一个传送状态的通道”,或者干脆是用于读取其它外部代码的“状态的一个副本”的途径。
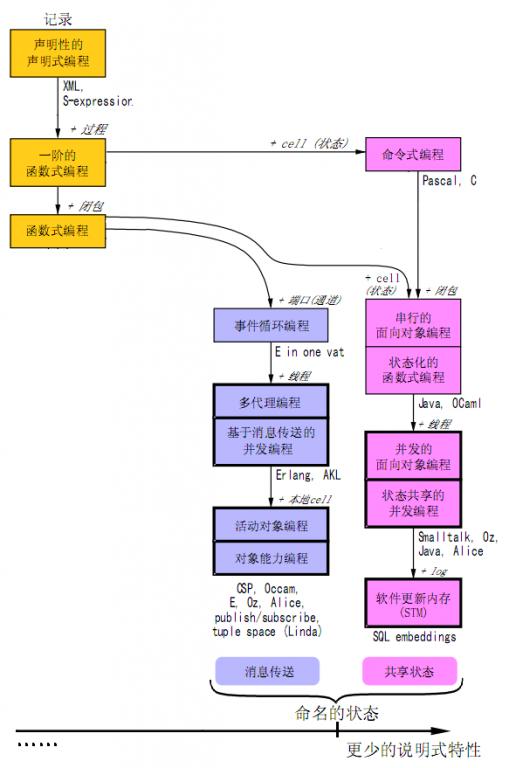
(图4)状态的命名
对于上述特性,erlang在整个过程中允许为状态命名(全局的或局部的)——变量。但是,该变量只能一次赋值——向端口和进程ID传递消息是一次性的,而函数参数上的变量赋值/匹配也是一次性的。尽管对状态“是否已赋值”需要进行有效性检测,从而给系统带来风险,但也是使得程序可读性和应用性能变得“稍微好一些”的唯一方式。
在“主要的编程范型”图中,缘于erlang对“命名的状态”的取舍,它被归为了“更少的说明式特性”的范畴。但同样的原因,它也是我们目前“(相对)最易用”的工业级的纯函数式语言。
同样,在这个分支上还有一个后起之秀,就是“对象能力编程”。这在最近的报道中,已有基于Scala的Actor模型进行的实现。尽管Scala是在Java上的一个实现,但它拥有完整的函数式语言特性,并使用了面向对象的一些语法与思想,在加入“对象能力类型(Object Capability Types,OCT)”之后,它拥有了跨Actor传递对象(整个对象可以视为一个状态/cell)的能力——在必要的时候,目标Actor会将接收到的对象再次本地化(local cell)。
八、语言的底本:LISP/Scheme/Haskell, Prolog, Fortran/Pascal, ML
从语言沿革的进化关系来看,Fortran位于高级语言的基底位置,基本上来说,它是现今绝大多数过程式/命令式语言的底本,在这个分支上主要发展的有Algol、Simula、Pascal与C。后来出现的各种面向对象编程语言,主要受到Simula跟Smalltalk的影响。
从Fortran之后,LISP成为所有函数式语言的底本,但由于早期LISP的应用性极差,所以Scheme吸取了Algol与LISP的一些特性,成为函数式语言发展的主要力量之一。在1987年之后,从Scheme、Smalltalk等演化出来的Haskell,也成为不可小视的新生力量。
(图5)函数式语言的庞大家族
Prolog这个语言的独特的开创性在于:它主要描述通过逻辑事实进行推论并得出结论的过程,它的运算对象并非直接含义上的“数据”,而是一种接近人的思维的抽象:逻辑子句。这种新的、对数据的抽象开启了一个语言分支。
在图中几乎总是与Scheme一起出现的ML(Meta Language)是一种,它的一个比较普及的、方言化的实现是SML(Standard ML)。在这个语言分支上,一个更晚出现而又颇富盛名的语言是Caml/OCaml(Caml, Categorical Abstract Machine Language)。基本上,它看起来象是在ML的函数式语言特性上加上:
- 命名(持久性常量)
- cell
Objective Caml (OCaml)支持面向对象编程,而使它更为众所周知的是:ECMAScript Ed4(Javascript 2)的标准规范,是采用OCaml这个语言来“定义”——并同时实现的。而微软的F#也是基于OCaml在函数式语言上方向上发展的。
另一个函数式的分支是数据流编程,它的底本语言是Dataflow——图中出现的Pipes/MapReduce是两种不同的机制,而非确定的语言。在这个分支上,现实中主要采用数据流编程范型的语言其实是LabVIEW。相对于数据流(驱动的)编程来讲时,命令式语言也被称为控制流(驱动的)编程语言。数据流编程在函数式这个分支中也是有开创意义的,它带来了图化、网络图化编程这样一种格局。
在这一小节(以及图)里面,主要提及到的底本语言的出现时间为:
- 1957 FORTRAN
- 1958 ALGOL
- 1960 LISP
- 1962 SIMULA
- 1969 Smalltalk
- 1970 Prolog
- 1971 Dataflow
- 1972 C
- 1973 ML
- 1975 Pascal
- 1975 Scheme
- 1990 Haskell
- 1996 OCaml
延伸阅读:
